记 AI Coding 的三个月

Harness engineering 这个概念开始变流行的时候,某种程度上也预示着 AI coding 真正到了可用阶段,背后是模型能力和 agent 能力共同提升的结果。
想起来在年初的时候,我还是个传统的 chatbox boy,需要先把思路聊明白,再自己手搓一遍。当时我不够信任 AI 的能力,坚信在动手之前必须先搞明白自己在干什么。后来我逐渐从让 agent 写单元测试开始,从此便一发不可收拾,逐渐变成了 Claude Code 和 Codex 重度用户。
Coding
我认为 AI coding 最适合的场景就是个人项目。因为你不用完全搞明白它写了什么,也不用太关心稳不稳定,只要能跑就行,写起来心理负担最小。同时,个人项目只是 just for fun,不值得花太多时间了解全部的细节。
最近我把博客从 Typlog 迁移到了自建的 Ghost。自建嘛,价格更便宜,但是从可用性到访问性能都需要自己亲力亲为。之前之所以托管在 Typlog,图的就是花钱买省心。不过现在在 AI 帮助下,10 秒写完迁移脚本,30 秒拉起 Ghost 系统,又花了 30 秒导入数据。That's it!
好吧,我承认现在 SaaS 公司被杀估值不是没有道理的。
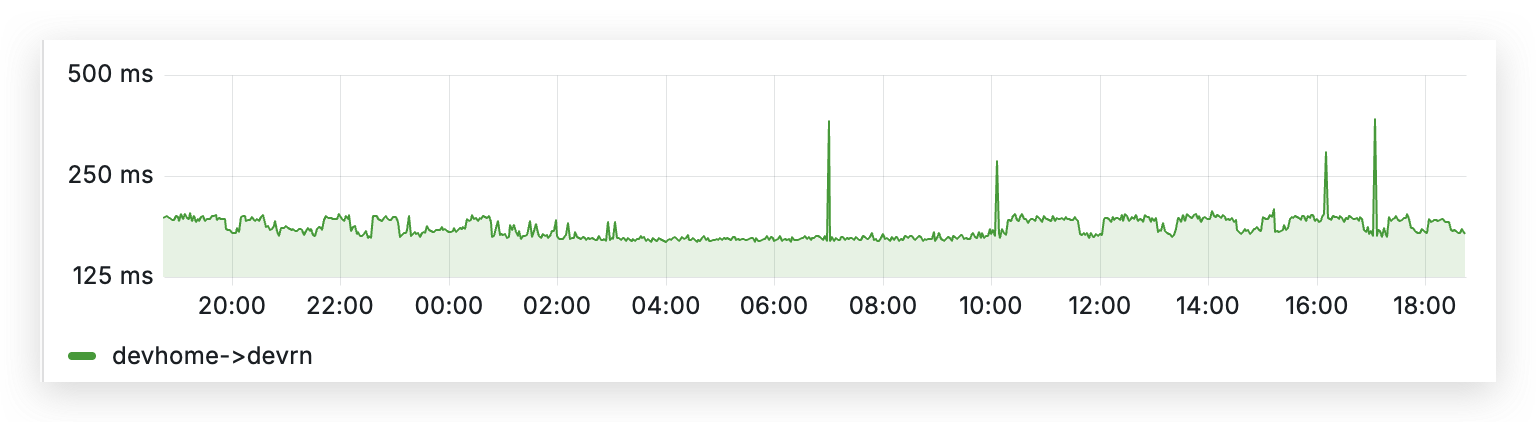
除此之外,还需要建一个大盘来监控服务器运行状态,在挂掉的时候能迅速通知到我。其实也做不了什么,总不能再搞个负载均衡吧?这就偏离便宜的初衷了。但有总比没有强,是吧?不过我自己对 Prometheus、Grafana 和时序数据库本身一窍不通,但还是花了几个小时完成了 hping3-exporter 和一个仪表盘,看起来还是挺专业的,不是吗?
我还做了一个 token 大盘,token-exporter,已经在 GitHub 上开源了。
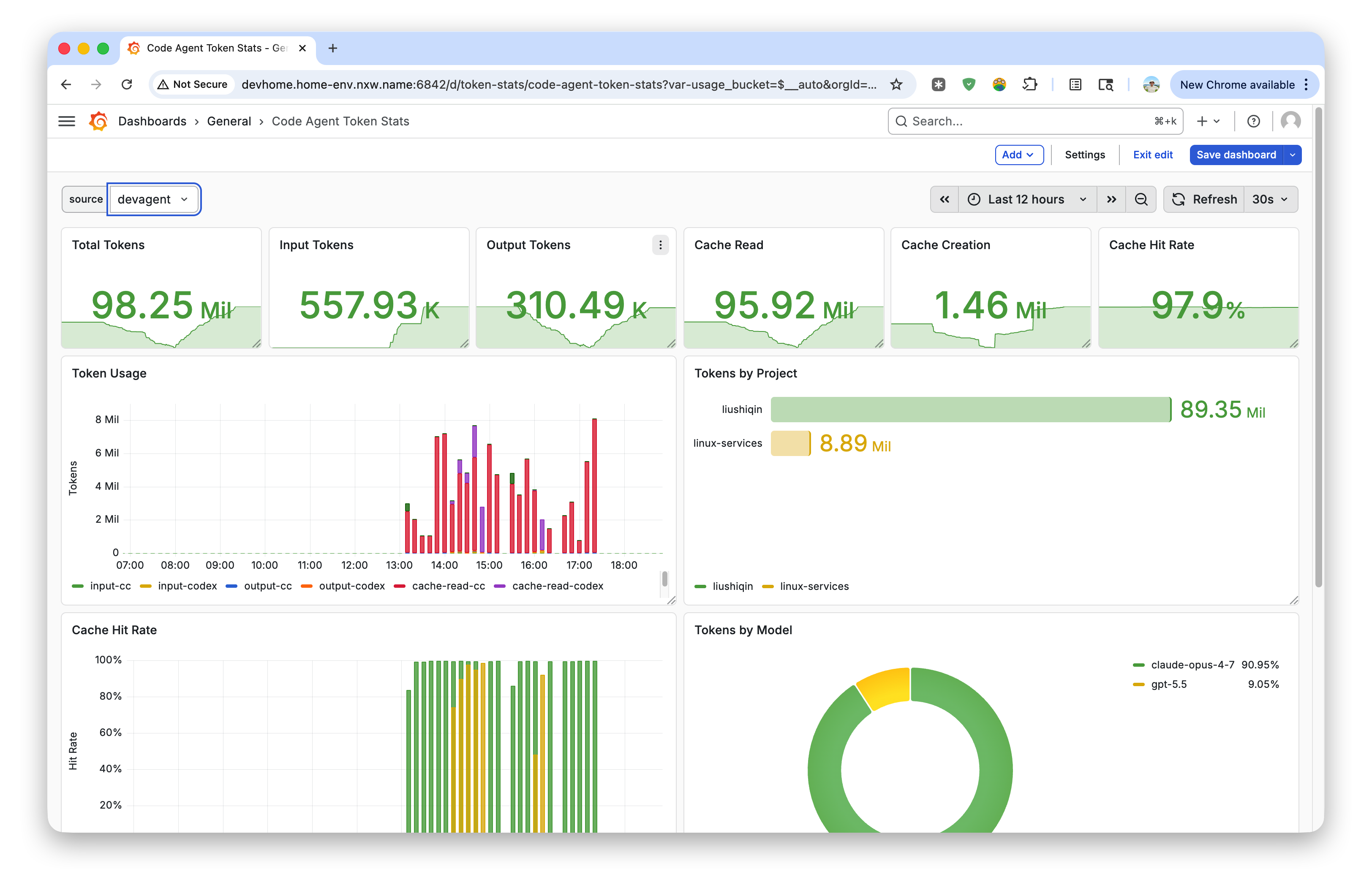
为什么要做这个?
很多人信奉 token maxxing,Meta 前段时间搞了一个 token 消耗量排行榜。我无意证明 token maxxing 和 task maxxing 谁对谁错,但是我想 token 可以大致反应生产力。我原来用 Session 和 WakaTime 衡量每天的工作量,现在 token 消耗量可以用作工作量证明的补充。当然,我也想看看我每个月的 $200 到底用了多少 token、用到了哪些项目上、产生了什么价值。
再来说说我的一些感悟和踩坑。
模型不是万能的。当你无法把效果描述出来时,当脑子里的效果和 prompt 存在 gap 时,模型也无能为力。我在做 token 大盘的时候,并不知道用什么类型的图表更适合展示一段时间内的 token 消耗量,我尝试说了一系列可能的图表名称让模型帮我实现,我只能不断说“不,这不是我想要的”,这个时候就相当的无助了。
尽量把指令一次性描述清楚。如果模型执行一段时间后再修改或增加需求,最终会演变成“屎上雕花”。如果不得不这么做,需要明确修改边界:模型哪里可以改,哪里不能改。如果持续地越改越糟,尽早 reset 并 redo 是明智的选择。
每次到达一个 milestone 的时候,都应该让模型总结做了什么。人是懒惰的,当一切跑起来之后,怎么实现的似乎就没那么重要了。不过如果你完全不了解细节,遇到一些复杂问题时,模型也会偷懒并原地打转,修了问题 A,出现问题 B -> 修复问题 B,又出现问题 A -> ...
最后,你应该适应适度脱离掌控的感觉,利用单元或者集成测试约束模型。毕竟逐字逐句把关,那提效就相当有限了。
Learning
如果说在个人项目中,AI coding 让你很舒服,那么在学习过程中,人就成了瓶颈。我最近在学习 CUDA C++ 写算子,AI 可以很快用人话总结要点,但依然需要人串行地、逐字逐句地理解。学习和 coding 的 token 消耗量也同样说明了这个问题。
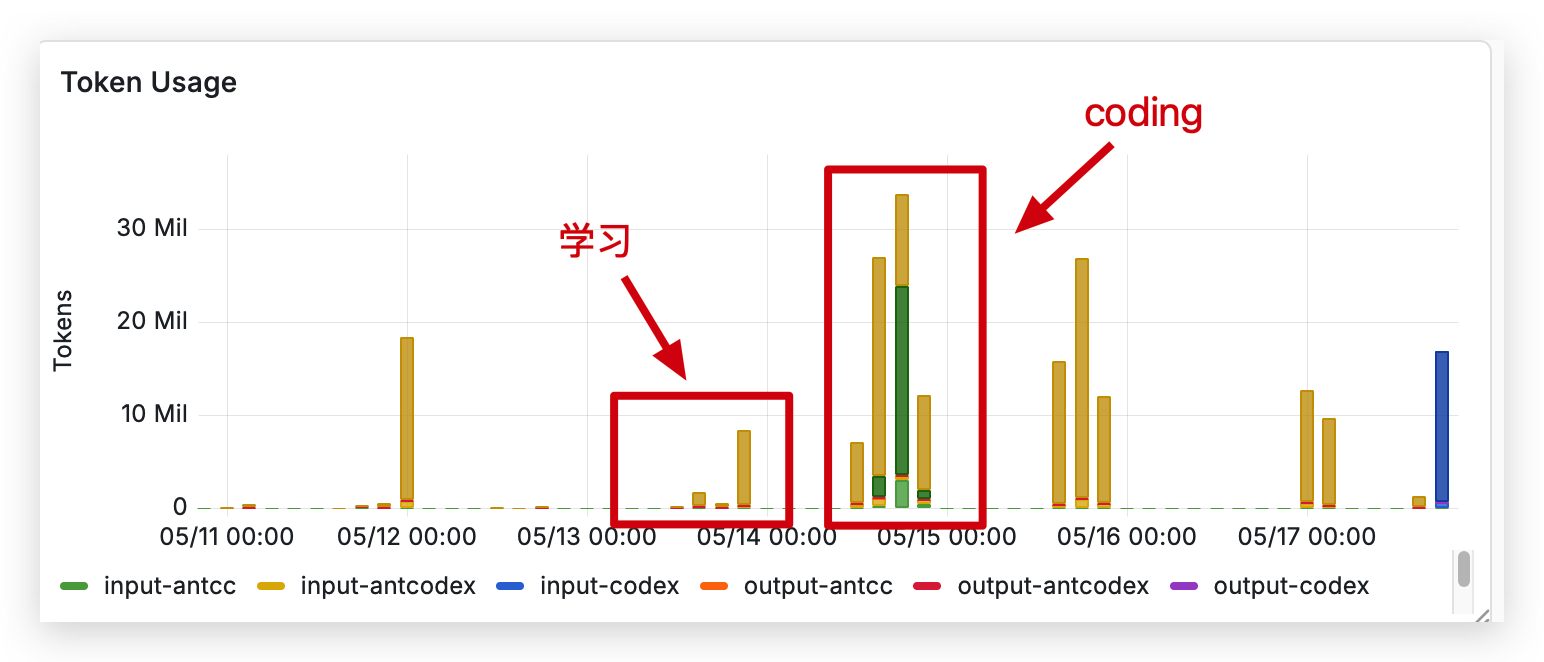
我的方案是把需要串行理解的文本转换为 coding。在学习 SGEMM 优化的时候,原作者写了 12 个 kernels 逐步优化 GEMM 算子。随着性能提升,优化过程也越来越难理解。随着复杂度提高,慢慢地大模型也不说人话了。
我让模型把计算过程制作成可视化的 HTML 动画,就像下面这样。
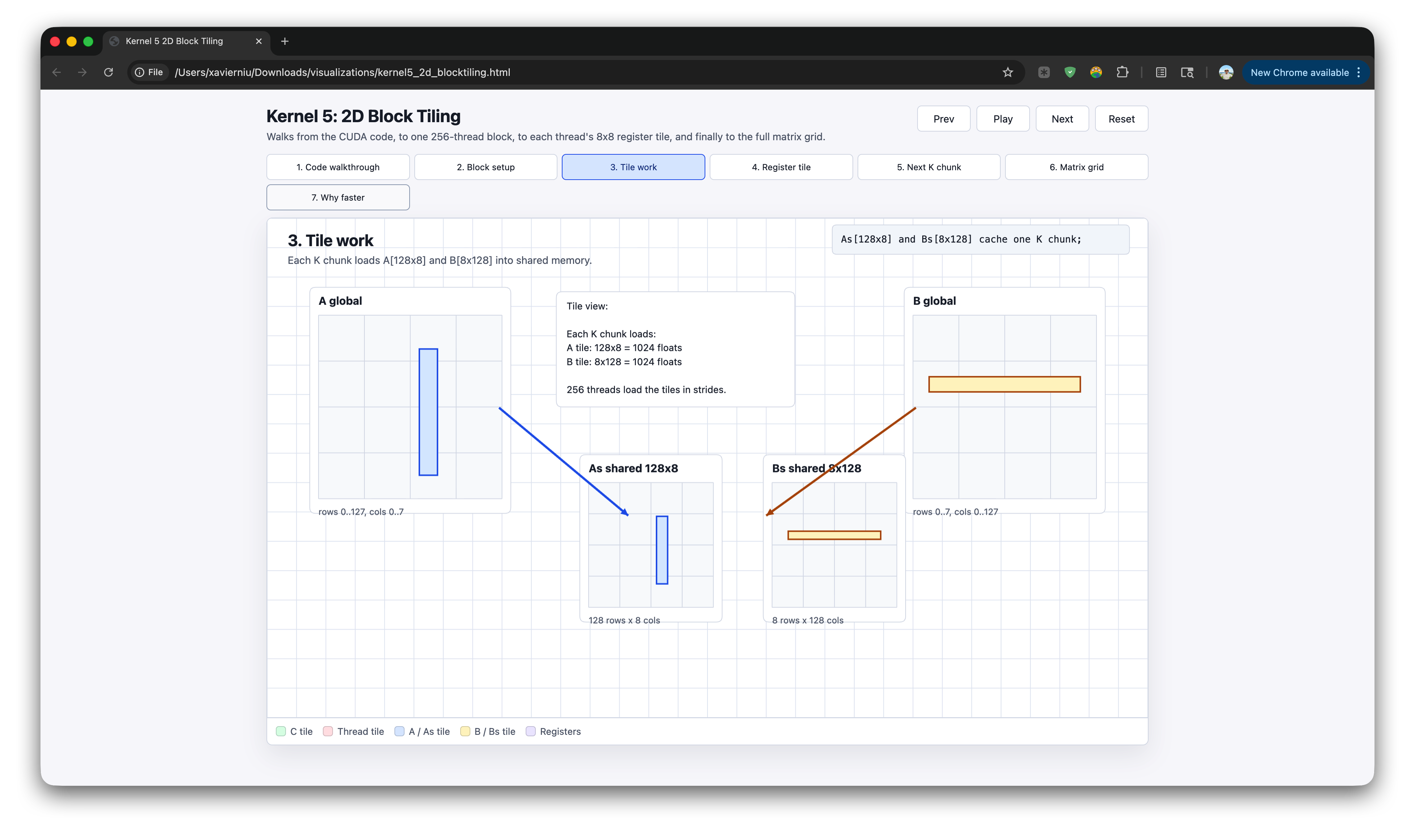
把 token 转换人更擅长理解的图片,这在一定程度上可以加速学习的过程。不过,人的学习速度以及专注力依然是 AI 时代最大的瓶颈。
Future
代码从手工迈向工业级的趋势已经毫无悬念了,或许原先执着地代码洁癖也是时候该放下了。我们最终会不会成为富士康产线上的质量检验工人?